
Produktklassifizierung und Textoptimierung mit Python und LLMs
Automatische Produktklassifizierung und Textoptimierung mit Python und LLMs
Ich habe ein kleines, aber nützliches Python-Skript entwickelt, das Produktdaten aus einer CSV-Datei einliest, automatisch einer passenden Kategorie zuordnet und die Beschreibung optimiert. Die Idee dahinter war es, zu testen, wie gut sich Large Language Models (LLMs) wie „gemma3:4b“ für solche Aufgaben eignen. Dabei kombiniere ich Pandas für die Datenverarbeitung mit einer einfachen API-Anbindung, um die Produktinformationen zu erweitern. Das Skript ist zwar kein komplexes KI-System, aber es zeigt, wie sich mit wenigen Zeilen Code manuelle Arbeitsschritte automatisieren lassen – besonders im Bereich E-Commerce oder für größere Produktkataloge.
In meinem Ansatz beginnt alles mit der Funktion, die CSV-Daten einliest. Mithilfe von Pandas und StringIO verwandle ich einen einfachen CSV-String in ein DataFrame. Dieser Schritt ist essenziell, da er mir erlaubt, die Produktdaten in einer strukturierten Form weiterzuverarbeiten.
Der nächste Teil des Projekts dreht sich um die LLM-basierte Produktklassifizierung. Hier habe ich das Paket „ollama“ verwendet, um das Modell „gemma3:4b“ anzusteuern. In der Funktion, die ich „classify_product_llm“ nenne, definiere ich zunächst einen Systemprompt, der dem Modell klare Anweisungen gibt: Es soll den Produktnamen und die Beschreibung entgegennehmen und diese einem vorgegebenen Kategorien-Schema (wie Elektronik, Haushaltswaren, Kleidung oder Gartenartikel) zuordnen. Mir war dabei wichtig, dass das Modell ausschließlich den Kategorienamen zurückgibt, um Missverständnisse zu vermeiden.
Parallel dazu habe ich eine weitere Funktion hinzugefügt, „rewrite_description“, die sich auf die Optimierung der Produktbeschreibung konzentriert. Mit einem anderen Systemprompt sorge ich dafür, dass die bestehende Beschreibung SEO-optimiert und zugleich ansprechender formuliert wird. Hier war es mir besonders wichtig, die Balance zu finden zwischen technischer Präzision und einer natürlichen, verkaufsfördernden Sprache. Ich wollte vermeiden, dass neue Details hinzugefügt werden – der Text sollte lediglich verbessert und leserfreundlicher gestaltet werden.
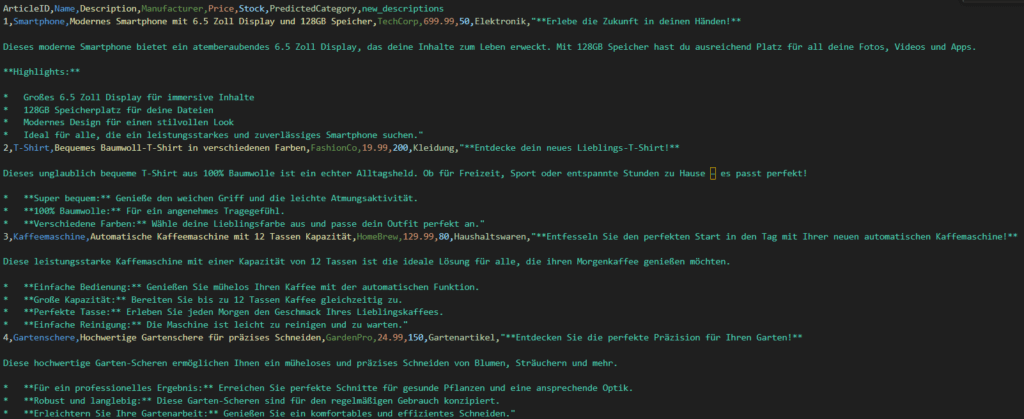
Um den Mehrwert der generierten Daten sichtbar zu machen, habe ich eine Funktion geschrieben, die über alle Produkte im DataFrame iteriert und sowohl die Klassifizierung als auch die Textoptimierung anwendet. In „enrich_data_with_classification“ sammle ich die Ergebnisse und erweitere den Datensatz um die neuen Spalten „PredictedCategory“ und „new_descriptions“. Beim Debugging und Testen des Codes habe ich an dieser Stelle viele Male Ausgaben in der Konsole verwendet, um sicherzustellen, dass jedes Produkt korrekt verarbeitet wird.
Im Hauptteil des Programms habe ich Beispiel-CSV-Daten definiert, diese eingelesen und dann die gesamte Verarbeitungskette durchlaufen lassen. Der finale Schritt, das Speichern des erweiterten DataFrames in einer CSV-Datei, rundet das Projekt ab. Diese Ausgabe in eine Datei ermöglicht es, die Ergebnisse auch extern weiterzuverwenden oder in andere Systeme zu importieren.