Ollama Menu – Schneller Desktop-Zugriff auf lokale KI-Modelle
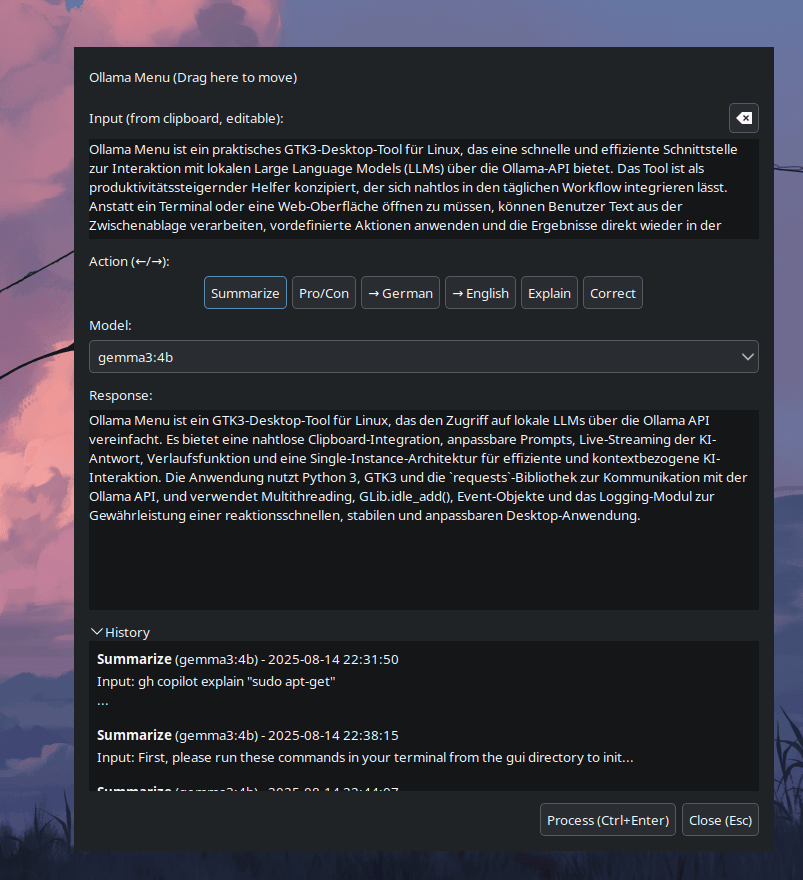
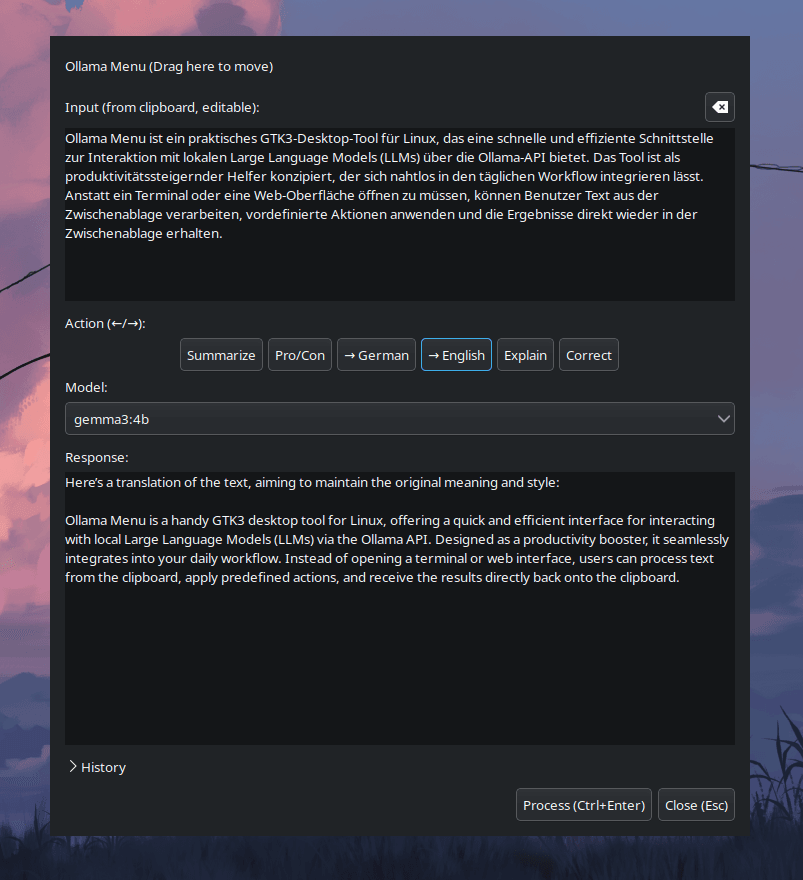
Ollama Menu ist ein praktisches GTK3-Desktop-Tool für Linux, das eine schnelle und effiziente Schnittstelle zur Interaktion mit lokalen Large Language Models (LLMs) über die Ollama-API bietet. Das Tool ist als produktivitätssteigernder Helfer konzipiert, der sich nahtlos in den täglichen Workflow integrieren lässt. Anstatt ein Terminal oder eine Web-Oberfläche öffnen zu müssen, können Benutzer Text aus der Zwischenablage verarbeiten, vordefinierte Aktionen anwenden und die Ergebnisse direkt wieder in der Zwischenablage erhalten.
Dieses Projekt entstand aus dem Bedürfnis, wiederkehrende Aufgaben wie das Zusammenfassen von Texten, das Übersetzen oder das Korrigieren von Code mit einem einzigen Tastendruck zu automatisieren, ohne den aktuellen Arbeitskontext verlassen zu müssen.
Wofür ist dieses Tool nützlich?
Für Entwickler, Autoren und Power-User, die Ollama lokal betreiben, löst dieses Tool ein zentrales Problem: den schnellen, kontextbezogenen Zugriff auf KI-Funktionen.
Effizienz: Verarbeitet markierten Text oder den Inhalt der Zwischenablage sofort, ohne den Fokus von der aktuellen Anwendung zu nehmen.
Anpassbarkeit: Benutzer können eigene, häufig genutzte Prompts (z.B. „Fasse diesen Text zusammen“, „Erkläre diesen Code“) in einer einfachen JSON-Datei definieren.
Workflow-Integration: Das Ergebnis einer Anfrage wird automatisch in die Zwischenablage kopiert, was eine sofortige Weiterverwendung ermöglicht.
Übersichtlichkeit: Eine saubere, unaufdringliche Oberfläche bietet schnellen Zugriff auf alle installierten Modelle und Aktionen sowie einen Verlauf früherer Anfragen.
Hauptmerkmale (Key Features)
Nahtlose Clipboard-Integration: Startet mit dem aktuellen Inhalt der Zwischenablage, der direkt bearbeitet werden kann.
Anpassbare Aktionen (Prompts): Eine externe prompts.json-Datei ermöglicht es Benutzern, eigene Aktionen mit spezifischen System-Prompts zu definieren und zu erweitern.
Dynamische Modellauswahl: Erkennt automatisch alle lokal über Ollama verfügbaren Modelle und listet sie in einem Dropdown-Menü auf.
Live-Streaming der KI-Antwort: Die Antwort des Modells wird in Echtzeit angezeigt, während sie generiert wird, was für eine exzellente User Experience bei längeren Antworten sorgt.
Verlaufsfunktion: Speichert die letzten 100 Anfragen (Input, Output, Modell, Aktion) und ermöglicht das schnelle Wiederherstellen und Kopieren vergangener Ergebnisse.
Single-Instance-Architektur: Stellt durch eine PID-Datei sicher, dass nur eine Instanz der Anwendung gleichzeitig läuft.
Effiziente Tastatursteuerung: Vollständige Bedienung über die Tastatur möglich (Pfeiltasten zur Aktionswahl, Ctrl+Enter zum Absenden, Esc zum Schließen).
Verwendete Technologien
Sprache: Python 3
GUI-Framework: GTK3 (über PyGObject)
Netzwerkkommunikation: requests-Bibliothek für die Interaktion mit der Ollama REST-API.
Nebenläufigkeit: threading-Modul zur Ausführung von Netzwerk-Anfragen im Hintergrund.
Datenformate: JSON für die Speicherung von Konfiguration (Prompts) und Anwendungsverlauf.
Technische Highlights und Lösungsansätze
Dieses Projekt demonstriert wichtige Konzepte der modernen Desktop-Anwendungsentwicklung:
Reaktionsfähige Benutzeroberfläche durch Multithreading:
Problem: Netzwerk-Anfragen an die Ollama-API können mehrere Sekunden dauern. Würden diese im Haupt-Thread ausgeführt, würde die gesamte Benutzeroberfläche einfrieren.
Lösung: Jede Anfrage an die KI wird in einem separaten Hintergrund-Thread (threading.Thread) gestartet. Dies hält die GUI jederzeit reaktionsfähig. Um die GUI-Komponenten (wie das Textfeld für die Antwort) sicher aus dem Hintergrund-Thread zu aktualisieren, wird GLib.idle_add() verwendet. Dies stellt sicher, dass alle UI-Updates im Haupt-Thread ausgeführt werden und verhindert Race Conditions.
Robuste Prozessverwaltung und User Experience:
Problem: Ein Benutzer könnte versehentlich eine neue Anfrage starten, während eine alte noch läuft.
Lösung: Ich habe eine Anforderungs-Abbruch-Logik mit threading.Event implementiert. Vor dem Start eines neuen Verarbeitungs-Threads wird geprüft, ob bereits einer läuft. Wenn ja, wird dem alten Thread ein Signal zum Abbrechen gesendet, bevor der neue gestartet wird. Dies sorgt für ein vorhersehbares Verhalten und verhindert überlappende Anfragen. Das Live-Streaming der Antwort gibt dem Benutzer zudem sofortiges Feedback.
Saubere Architektur und Konfiguration:
Problem: Hartcodierte Prompts und Einstellungen machen eine Anwendung unflexibel.
Lösung: Die Anwendung folgt dem XDG-Base-Directory-Standard, indem Konfigurationsdateien (prompts.json) in ~/.config und Anwendungsdaten (history.json) in ~/.local/share gespeichert werden. Dies trennt den Code von den Benutzerdaten und macht das Tool leicht anpassbar und wartbar.
Professionelles Anwendungs-Handling:
Die Implementierung der Single-Instance-Sperre über eine PID-Datei (/tmp/ollama-menu-python.pid) ist eine bewährte Methode, um zu verhindern, dass Benutzer versehentlich mehrere Fenster öffnen, was zu Verwirrung und unnötigem Ressourcenverbrauch führen würde.
Strukturiertes Logging (logging-Modul) und sauberes Exception-Handling sorgen für Stabilität und erleichtern die Fehlersuche.