Customer Segmentation via RFM Analysis
Im E-Commerce ist nicht jeder Kunde gleich. Während einige regelmäßig und viel kaufen, sind andere vielleicht nur Einmalkäufer oder drohen abzuwandern. Um Marketingbudgets effizient einzusetzen, ist es essenziell, diese Gruppen zu unterscheiden.
In diesem Projekt habe ich eine RFM-Analyse (Recency, Frequency, Monetary) auf einem realen Datensatz eines britischen Online-Händlers durchgeführt. Ziel war es, Kunden basierend auf ihrem Kaufverhalten in strategische Segmente zu unterteilen.
Was ist die RFM-Analyse?
Die RFM-Methode bewertet Kunden anhand von drei Dimensionen:
- Recency (Aktualität): Wie viele Tage sind seit dem letzten Kauf vergangen?
- Frequency (Häufigkeit): Wie oft hat der Kunde insgesamt bestellt?
- Monetary (Umsatz): Welchen Gesamtumsatz hat der Kunde generiert?
Jeder Kunde erhält für jede Dimension einen Score (in meinem Skript von 1 bis 4), woraus sich ein Gesamt-Score ergibt.
Technische Umsetzung mit Python
Für die Analyse habe ich Python mit Pandas für die Datenverarbeitung und Seaborn für die Visualisierung genutzt.
1. Datenbereinigung
Der Datensatz (“Online Retail”) enthält über 500.000 Transaktionen. Zunächst mussten die Daten bereinigt werden:
- Entfernung von Transaktionen ohne
CustomerID. - Herausfiltern von Stornierungen (Rechnungsnummern mit ‘C’).
- Bereinigung von fehlerhaften Daten (negative Preise oder Mengen).
# Auszug aus dem Cleaning-Prozess
df = df.dropna(subset=['CustomerID'])
df = df[~df['InvoiceNo'].astype(str).str.contains('C')]
df['TotalPrice'] = df['Quantity'] * df['UnitPrice']2. Berechnung der Metriken
Anschließend habe ich die Daten auf Kundenebene aggregiert:
latest_date = df['InvoiceDate'].max() + dt.timedelta(days=1)
rfm = df.groupby('CustomerID').agg({
'InvoiceDate': lambda x: (latest_date - x.max()).days, # Recency
'InvoiceNo': 'nunique', # Frequency
'TotalPrice': 'sum' # Monetary
})Ergebnisse und Insights
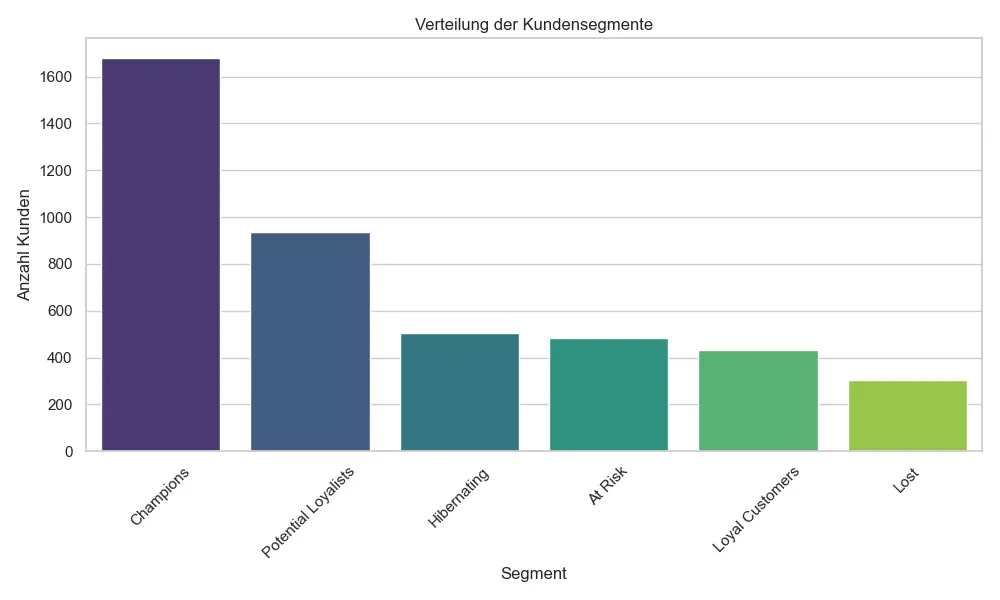
Die Analyse hat klare Kundensegmente offenbart. Hier ist die Verteilung der identifizierten Gruppen:
Strategische Ableitungen & Handlungsempfehlungen
Die Datenanalyse ist nur der erste Schritt. Der eigentliche Mehrwert entsteht durch die Ableitung konkreter Maßnahmen für den Marketing-Mix (E-Mail, SEA, Social). Basierend auf den Daten habe ich folgende Strategien entwickelt:
1. Champions (38% der Kunden)
- Charakteristik: Kaufen oft, viel und erst kürzlich.
- Strategie: Retention & Belohnung. Diese Gruppe braucht keine Rabatte, um zu kaufen.
- Konkrete Maßnahmen:
- Exklusivität: Early Access zu neuen Kollektionen oder “Secret Sales”.
- Referral-Marketing: Incentivierung für das Werben neuer Kunden (“Freunde werben Freunde”).
- Community Building: Einladung zu exklusiven Events oder VIP-Gruppen.
2. Potential Loyalists (21% der Kunden)
- Charakteristik: Gute Frequenz, aber noch kein Top-Umsatz oder leicht sinkende Aktualität.
- Strategie: Upselling & Cross-Selling. Ziel ist es, den Warenkorbwert und die Frequenz zu erhöhen.
- Konkrete Maßnahmen:
- Personalisierte Empfehlungen: “Kunden, die X kauften, mochten auch Y” (per E-Mail-Automation).
- Schwellen-Boni: “Kaufe für noch 20€ mehr und erhalte kostenlosen Versand/Geschenk.”
- Treueprogramm: Einführung eines Punktesystems, um den nächsten Kauf anzureizen.
3. At Risk & Hibernating (22% der Kunden)
- Charakteristik: Hoher historischer Wert, aber lange inaktiv (> 6 Monate). Hier droht Abwanderung (Churn).
- Strategie: Win-Back / Reaktivierung.
- Konkrete Maßnahmen:
- Automatisierte E-Mail-Flows: Sequenz nach 90/180 Tagen Inaktivität.
- Incentives: Aggressive Rabatte (z.B. “15% Willkommen-Zurück-Gutschein”) oder zeitlich begrenzte Angebote.
- Umfragen: “Warum hast du lange nicht bestellt?” – Feedback nutzen, um Prozesse zu verbessern.
4. Sonderfall: “The Lost Whales” (Analytischer Deep Dive)
Bei der Analyse fiel mir ein spezifischer Kunde (ID 12346) auf: Einmaliger Umsatz von über £77.000, aber seit fast einem Jahr inaktiv.
- Interpretation: Dies ist kein Fall für automatisierte Newsletter. Es handelt sich wahrscheinlich um einen B2B-Großkunden oder ein einmaliges Projektgeschäft.
- Maßnahme: Persönlicher Vertriebskontakt. Hier sollte ein Key Account Manager zum Telefon greifen, statt eine automatisierte “Wir vermissen dich”-Mail zu senden. Dies zeigt, wie wichtig die manuelle Prüfung von Ausreißern (Outliers) ist.
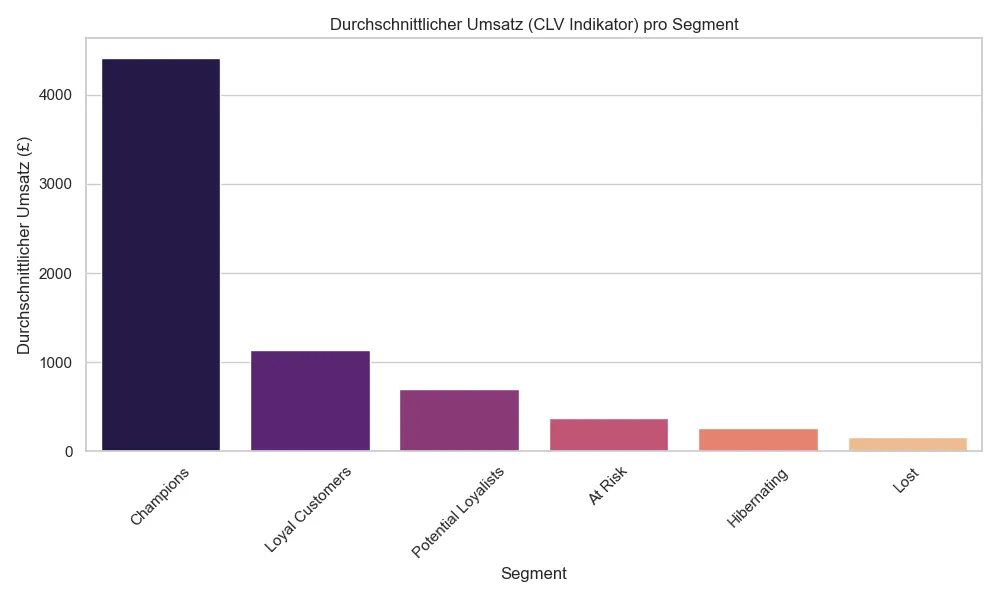
Visualisierung: Wer sind die wertvollsten Kunden?
Ein Blick auf den durchschnittlichen Umsatz (Monetary Value) pro Segment bestätigt die Wichtigkeit der “Champions”:
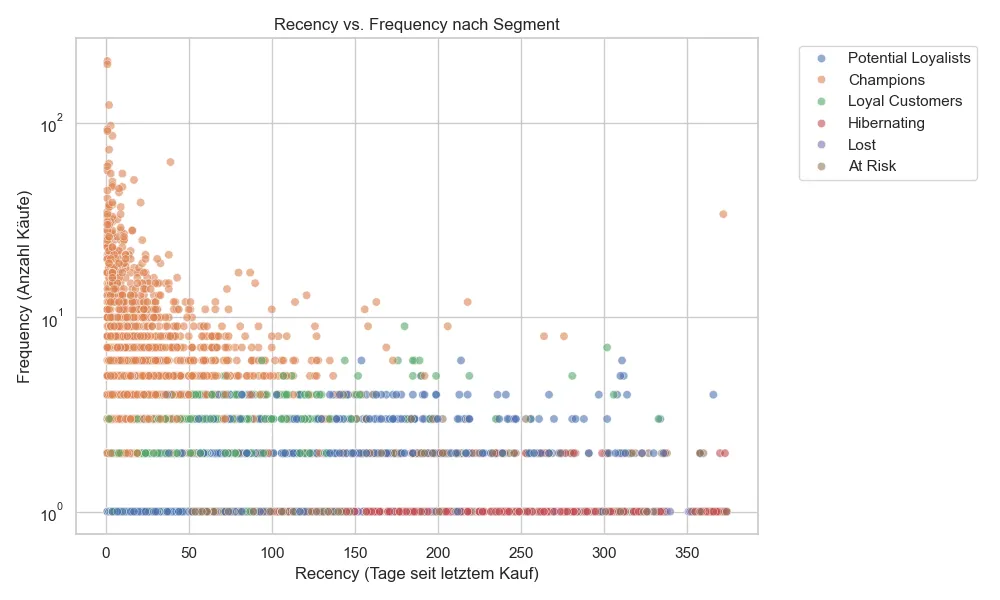
Zusätzlich zeigt der Scatter-Plot die Korrelation zwischen Aktualität (Recency) und Häufigkeit (Frequency). Man sieht deutlich, dass die “Champions” (oben links) sehr häufig und erst vor kurzem gekauft haben, während “Lost” Kunden (unten rechts) selten und vor langer Zeit aktiv waren.
Fazit
Durch dieses Python-Skript konnte ich einen rohen Transaktionsdatensatz in handlungsrelevante Marketing-Insights verwandeln. Anstatt alle Kunden mit dem gleichen Newsletter zu beschießen, ermöglicht diese Segmentierung eine personalisierte Ansprache, die nachweislich die Conversion-Rate und den Customer Lifetime Value erhöht.
Dieses Projekt demonstriert meine Fähigkeit, technische Data-Science-Methoden direkt auf betriebswirtschaftliche Fragestellungen im E-Commerce anzuwenden.
👉 Wie geht es weiter? In meinem Projekt Personalisierung & A/B-Testing zeige ich, wie man diese Segmente technisch nutzt, um dynamische Landingpages auszuspielen.