
Web-Scraping und Datenbankinteraktion mit Python
In diesem Portfolio-Beitrag wird der Prozess des Web-Scrapings der Flaschenpost-Website mithilfe von Python und SQLite detailliert beschrieben. Dabei liegt der Fokus auf dem Verständnis der verwendeten Datenstrukturen, der Werkzeuge und der Implementierungstechniken.
Schritt 1: Kategorien und Links
Zuerst identifizierte ich die statischen URLs für die Kategorien auf der Flaschenpost-Website. Dank ihrer Konsistenz war es einfach, diese Links zu finden und zu verwenden, um die Produktseiten zu durchsuchen. Durch das Scrapen dieser Kategorien konnte ich die URLs der einzelnen Produkte extrahieren.
Beispiele:
obst-gemuese/obst
obst-gemuese/gemuese
obst-gemuese/salat
obst-gemuese/kraeuter
obst-gemuese/trockenfruechte-kerne
kuehlregal/frisch-fertig
kuehlregal/fleisch-fisch-veggie

Schritt 2: Netzwerkanalyse mit Firefox
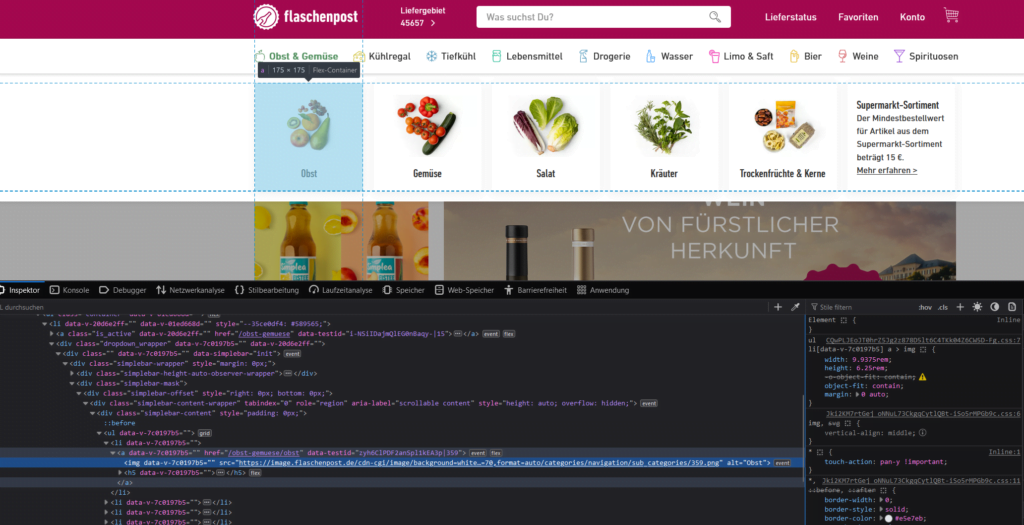
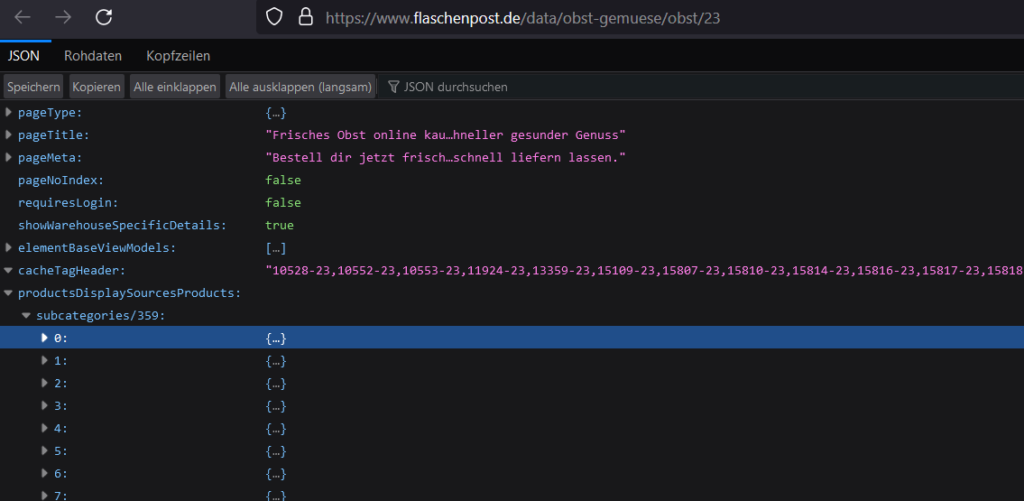
Um das genaue Format der Daten zu verstehen, das von der Flaschenpost-Website zurückgegeben wurde, nutzte ich das Firefox-Netzwerkanalysetool. Besonders interessant war die URL „https://www.flaschenpost.de/data/[KATEGORIE]/23„, die eine JSON-Liste der Artikel lieferte.
Durch die Analyse der Netzwerkanfragen konnte ich feststellen, wie die Daten strukturiert sind und welche Endpunkte ich für das Scraping verwenden muss. Dies ermöglichte es mir, gezielt auf die benötigten Informationen zuzugreifen und sie effizient zu extrahieren.
Schritt 3: Datenstruktur und Datenbankdesign
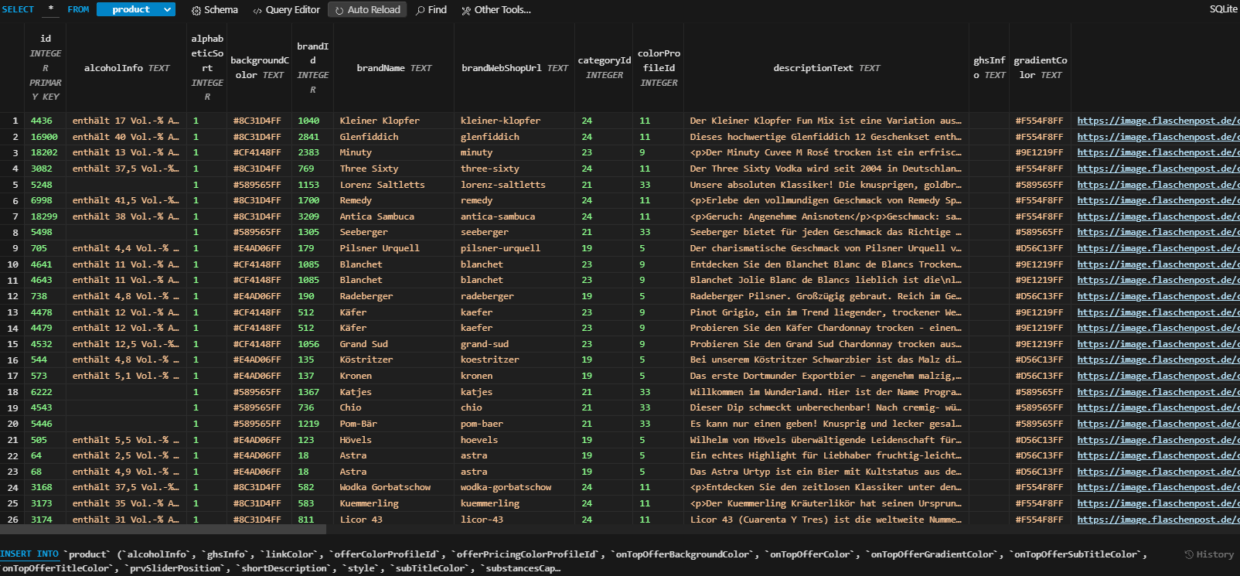
Die Analyse der JSON-Daten ergab, dass es bei Flaschenpost sowohl Produkte als auch Artikel gibt. Produkte repräsentieren Hauptartikel, während Artikel deren Varianten darstellen. Basierend auf dieser Struktur entwarf ich eine SQLite-Datenbank mit den entsprechenden Tabellen:
product: Diese Tabelle enthält Informationen über die Hauptprodukte, einschließlich ihrer Eigenschaften wie ID, Name, Beschreibung und Herstellerdetails.
articles: Hier werden die einzelnen Artikel gespeichert, die zu den Produkten gehören. Dies umfasst Daten wie ID, Preis, Verfügbarkeit und andere spezifische Informationen zu jeder Variante.
allergenes: In dieser Tabelle werden Allergene gespeichert, die den Produkten zugeordnet sind. Jedes Allergen hat eine eindeutige ID und einen Namen.
details: Hier werden zusätzliche Details zu den Produkten und Artikeln gespeichert, wie z.B. Einheit, Volumen und andere spezifische Eigenschaften.
imagesBig: Diese Tabelle enthält URLs zu großen Bildern der Produkte und Artikel, die für die Anzeige benötigt werden.
Durch die Aufteilung der Daten in separate Tabellen wird die Struktur der Datenbank übersichtlich gehalten und die Abfrageeffizienz verbessert. Dies ermöglicht eine einfache Verwaltung und Abfrage von Informationen während des weiteren Entwicklungsprozesses und erleichtert die Skalierung der Anwendung.
Schritt 4: Datenextraktion und Datenbankintegration
Nachdem ich die Kategorien identifiziert und die Datenstruktur analysiert hatte, begann ich mit dem Scrapen der Flaschenpost-Website. Dieser Prozess erfolgte in mehreren Schritten, wobei ich mich auf das Parsing der HTML-Seiten und das Extrahieren der JSON-Daten konzentrierte, um die Informationen in die SQLite-Datenbank einzuspeisen.
Parsing der HTML-Seiten
Um die benötigten Daten zu extrahieren, habe ich BeautifulSoup verwendet, um die HTML-Seiten der Flaschenpost-Website zu parsen. Durch das gezielte Navigieren durch das DOM (Document Object Model) konnte ich die relevanten Abschnitte identifizieren, die die URLs enthalten, die ich für das Scrapen benötigte.
Extrahieren der JSON-Daten
Nachdem ich die relevanten HTML-Seiten identifiziert hatte, extrahierte ich die JSON-Daten, die sie enthielten. Dies erfolgte mithilfe von Python-Code, der die HTML-Struktur durchlief und die JSON-Informationen extrahierte. Dabei orientierte ich mich an den Mustern und Tags auf den Seiten, um die richtigen Daten zu finden und zu extrahieren.
Die eigentliche Extraktion der Daten erfolgt in der Funktion scrape_data(value). Diese Funktion nimmt eine Kategorie (value) als Eingabe und erstellt eine URL, um die Daten von der entsprechenden Seite abzurufen. Nachdem die Daten erhalten wurden, werden sie im JSON-Format gespeichert. Der Dateiname wird durch Ersetzen von Schrägstrichen (/) in der Kategorie durch Bindestriche (-) erstellt. Die heruntergeladenen JSON-Dateien werden im zuvor erstellten Ordner gespeichert.
Um den Scraping-Prozess zu beschleunigen, habe ich den ThreadPoolExecutor aus der concurrent.futures-Bibliothek verwendet. Dies ermöglicht paralleles Scraping von mehreren Kategorien gleichzeitig, was die Gesamtlaufzeit des Scraping-Vorgangs verkürzt. Jede Kategorie in der value_list wird an die scrape_data-Funktion übergeben, um die Daten herunterzuladen.
Dieser Ansatz ermöglicht es, eine große Menge an Daten effizient von der Website zu extrahieren und in einem strukturierten Format zu speichern, was später für die weitere Verarbeitung und Analyse verwendet werden kann.
Schritt 5: Das Herunterladen der Produktbilder
In diesem Schritt geht es darum, Bilder herunterzuladen, die mit den Produkten in der Datenbank verknüpft sind. Das Herunterladen von Bildern kann nützlich sein, um eine visuelle Darstellung der Produkte in einer Anwendung oder Website bereitzustellen.
Zunächst extrahieren wir aus der Datenbank die Informationen über die Bilder, die heruntergeladen werden sollen. Dazu nutzen wir eine SQL-Abfrage, um die erforderlichen Daten abzurufen:
Schritt 6: Anzeigen der Daten mittels Flask
Flask ist ein beliebtes Webframework für Python, das es uns ermöglicht, Webanwendungen schnell und einfach zu erstellen. Wir verwenden Flask, um eine Benutzeroberfläche zu erstellen, über die Benutzer Daten abrufen können.
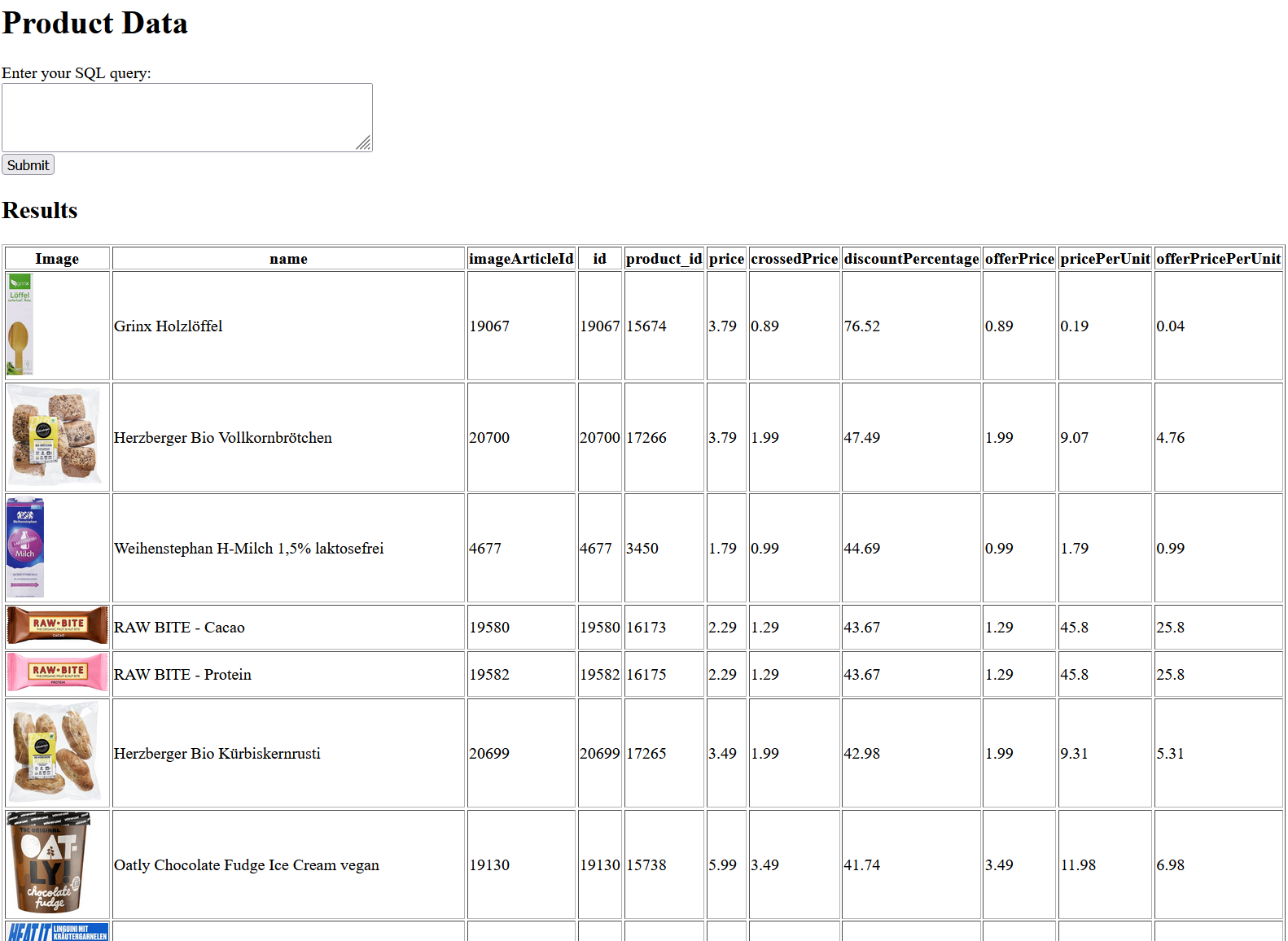
In dieser Flask-Anwendung definieren wir eine Route (/), die sowohl GET- als auch POST-Anfragen verarbeitet. Wenn ein Benutzer eine POST-Anfrage sendet (z. B. indem er ein Formular ausfüllt und absendet), wird die Benutzerabfrage an die Datenbank gesendet und die Ergebnisse werden auf derselben Seite angezeigt.
Die Abfrage wählt den Namen des Produkts, die Artikelkennung, die Produktkennung, den Preis, den durchgestrichenen Preis, den Angebotspreis, den Preis pro Einheit und den Angebotspreis pro Einheit aus den Tabellen articles und product aus. Sie berechnet den Rabattprozentsatz für jedes Produkt und filtert nach Produkten mit dem TAG „Tagesangebot“ oder „TOP-ANGEBOT“, die verfügbar sind. Die Ergebnisse werden nach dem Rabattprozentsatz absteigend sortiert.
Zusatz Funktion: Waren dem Warenkorb hinzufügen
Um Artikel dem Warenkorb hinzuzufügen, wird eine Anfrage an die entsprechende API des Flaschenpost-Webshops gesendet. Dabei wird eine JSON-Datenstruktur verwendet, um die Positionen der hinzuzufügenden Artikel zu definieren. In diesem JSON-Objekt werden die Artikel-ID, die Herkunft des Artikels und die gewünschte Menge angegeben. Nachdem die Datenstruktur erstellt wurde, erfolgt ein POST-Request an die API-Endpunkt-URL „https://www.flaschenpost.de/webshop-cart-api/api/v1/addCartPositions„, wobei die erforderlichen Cookies und Header übergeben werden. Die Serverantwort auf diese Anfrage enthält Informationen über den aktualisierten Warenkorb, wie z.B. die enthaltenen Artikel und deren Gesamtpreis.
json_data = {
‚positions‘: [
{
‚articleId‘: row[2],
‚articleOrigin‘: 1,
‚quantity‘: 1,
},
],
‚cartVersion‘: 40,
}
response = requests.post(
‚https://www.flaschenpost.de/webshop-cart-api/api/v1/addCartPositions‘,
cookies=cookies,
headers=headers,
json=json_data,
)
Mögliche Erweiterungen:
Preisvergleich und Preistracking:
Durch die regelmäßige Erfassung von Preisen für Produkte können Sie Trends im Preisverhalten erkennen, Preisschwankungen verfolgen und Wettbewerbsanalysen durchführen. Dies könnte es ermöglichen, Preisalarme einzurichten, um Benutzer über Preissenkungen oder -erhöhungen zu informieren.
Personalisierte Produktempfehlungen:
Basierend auf den bisherigen Einkäufen können personalisierte Produktempfehlungen generiert werden.
Bestandsverfolgung und Benachrichtigungen:
Durch die Überwachung des Lagerbestands bestimmter Produkte können Sie Benachrichtigungen senden, wenn ein Produkt wieder auf Lager ist oder wenn der Lagerbestand niedrig ist.
Abo-Einkauf:
Es steht keine Funktion zur Verfügung, die es ermöglicht seinen Einkauf erneut zu tätigen. Nun kann der Warenkorb automatisiert befüllt werden und eine Bestellung automatisiert werden.
LLM – Rezept Vorschläge:
Durch die verwendung von LLMs kann aufgrund der Daten in der Datenbank ein Gericht zusammengestellt werden. Beispiel: „Erstelle mir einen Warenkorb mit einem gesunden und günstigen Mittagsessen“