
ComfyUI – ControlNet
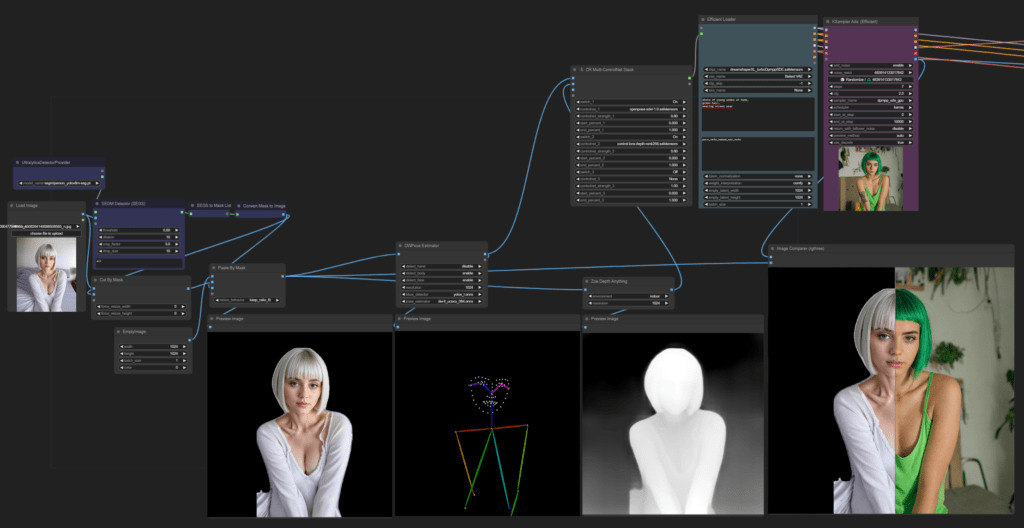
ComfyUI – ControlNet
Abhängigkeiten
ComfyUI – https://github.com/comfyanonymous/ComfyUI
SDXL Turbo Checkpoint – https://civitai.com/models/112902/dreamshaper-xl
4x-Ultrasharp – https://civitai.com/models/116225/4x-ultrasharp
ultralytics Yolov8 – https://github.com/ultralytics/ultralytics
model: yolov8m-seg.pt
DWPose – https://github.com/IDEA-Research/DWPose
model: DWPose-l 384×288
ZoeDepth – https://github.com/isl-org/ZoeDepth
model: indoor
ControlNet – https://huggingface.co/stabilityai/control-lora
model: control-lora-depth-rank256 -> Depth Input
ControlNet – https://huggingface.co/thibaud/controlnet-openpose-sdxl-1.0
model: openpose-sdxl-1.0 -> Pose Input
DWPose bietet eine diverse Palette von Modellen unterschiedlicher Größen an, die eine umfassende Erfassung der menschlichen Ganzkörper-Pose ermöglichen – von feingliedrigen bis hin zu umfassenden Ansätzen. Die Integration von DWPose anstelle von OpenPose in ControlNet resultierte in deutlich verbesserten Ergebnissen, insbesondere hinsichtlich der Bildgenerierung.

Durch die Verwendung von ZoeDepth kann ich hochwertige Tiefenkarten aus Bildern extrahieren, die dann nahtlos in meinen Workflow integriert werden können. Insbesondere leite ich diese Tiefenkarten weiter an ControlNet, wo sie als wichtige Eingabe für weitere Verarbeitungsschritte dienen.

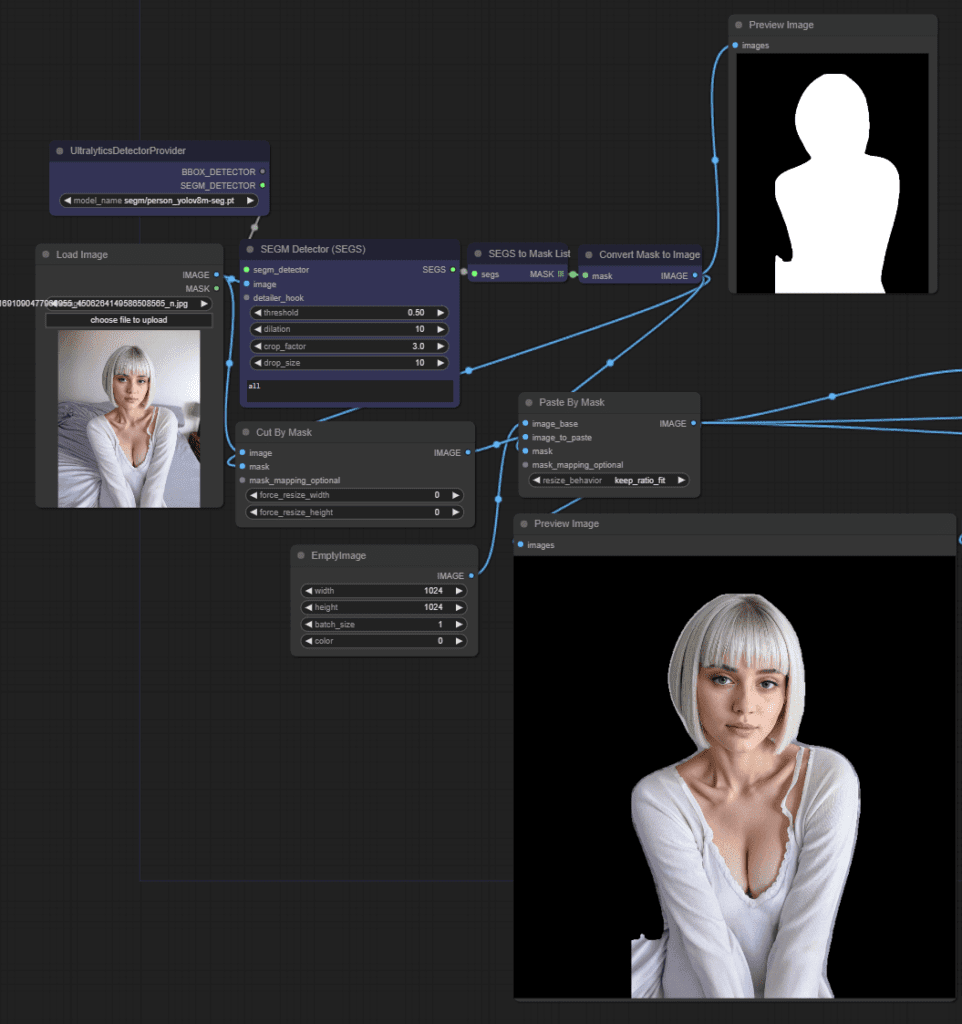
Ich nutze YOLOv8 speziell am Anfang meines Prozesses, um Personen präzise aus Bildern auszuschneiden und somit bessere Ergebnisse zu erzielen, insbesondere bei der Hintergrundentfernung. Durch die präzise Erfassung von Personen zu Beginn kann ich sicherstellen, dass die nachfolgenden Schritte in meinem Workflow auf einer soliden Grundlage aufbauen und zu hochwertigen Ergebnissen führen.
https://github.com/ultralytics/ultralytics
In meinem Workflow wird der erste Schritt durchgeführt, indem das Eingangsbild verarbeitet wird. Dabei wird die Person aus dem Bild präzise ausgeschnitten, um sie isoliert zu erhalten. Anschließend wird ein neues leeres Bild erzeugt, das die Abmessungen von 1000×1000 Pixeln aufweist.
Das isolierte Bild der Person wird dann über dieses neue 1000×1000 Bild gelegt. Dieser Schritt dient dazu, die Auflösung der ausgeschnittenen Person an das spätere Ausgabebild anzupassen. Durch diese Anpassung wird sichergestellt, dass die Person später im Ergebnisbild die richtige Größe und Proportionen hat und nahtlos in die Szene integriert werden kann.
Diese Vorgehensweise gewährleistet, dass die Qualität und Konsistenz des endgültigen Ergebnisses erhalten bleibt und eine reibungslose Integration der Person in die gewünschte Umgebung gewährleistet ist.
Nachdem die Person erfolgreich in das neue 1000×1000 Bild integriert wurde, wird im nächsten Schritt die Pose der Person mithilfe von DWPose ermittelt.
Sobald die Pose der Person ermittelt wurde, wird mit Hilfe von ZoeDepth ein Tiefenbild generiert. ZoeDepth ermöglicht es, aus einem einzelnen Bild metrische Tiefeninformationen abzuleiten, was von entscheidender Bedeutung ist, um ein realistisches und genaues räumliches Verständnis der Szene zu erlangen.
Durch die Kombination von DWPose und ZoeDepth werden nicht nur die Bewegungen und Positionen der Person erfasst, sondern auch die räumliche Tiefe der Szene. Dies ermöglicht eine noch präzisere und realistischere Darstellung der Person und ihrer Umgebung im späteren Ausgabebild.
Insgesamt stellt diese integrierte Vorgehensweise sicher, dass die Pose der Person sowie die räumliche Tiefe der Szene akkurat erfasst und dargestellt werden, was zu hochwertigen und realistischen Ergebnissen führt.
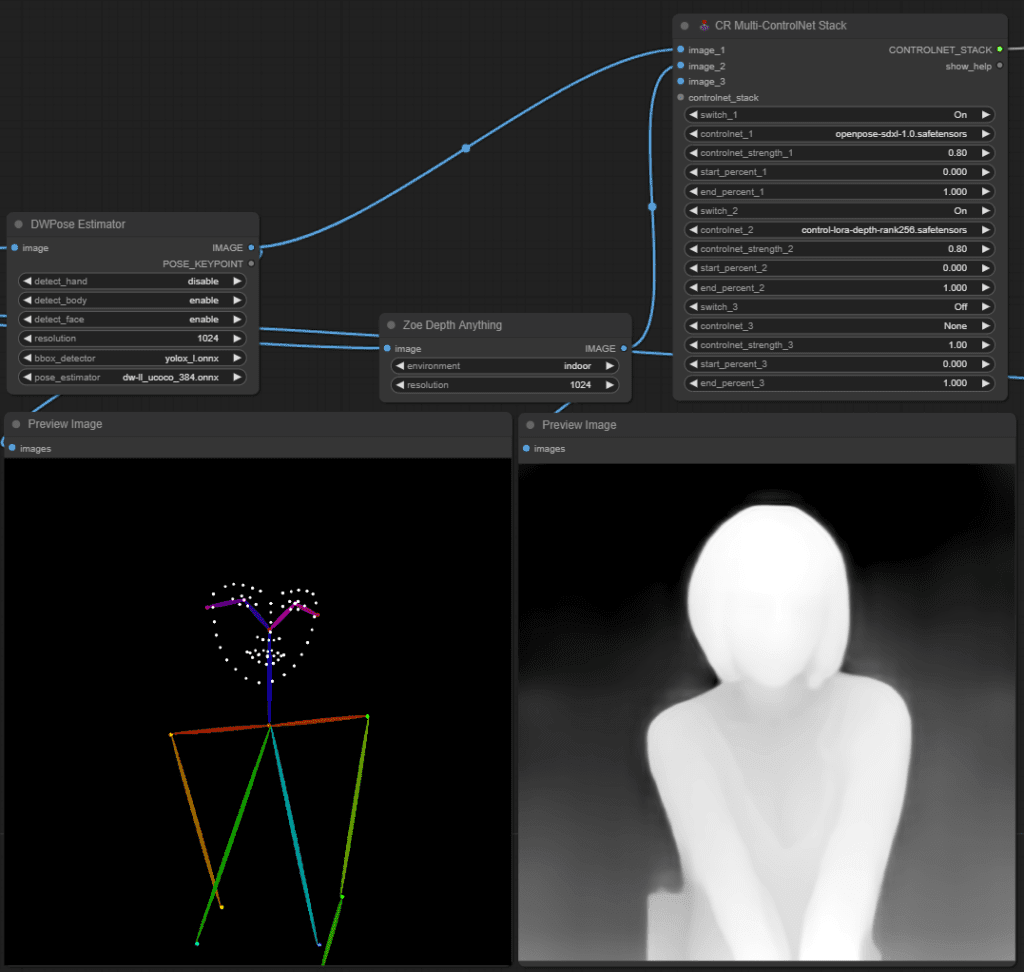
Im nächsten Schritt werden die Daten durch ein ControlNetStack geleitet. Das ControlNetStack übernimmt die Aufgabe, die Ausgabe von DWPose und ZoeDepth zu verarbeiten und sie für den weiteren Verarbeitungsprozess vorzubereiten.
Die verarbeiteten Daten werden dann an den Model Loader übergeben, der dafür zuständig ist, die benötigten Modelle und Gewichte zu laden, um die nächsten Schritte des Prozesses durchzuführen. Der Model Loader sorgt dafür, dass die richtigen Modelle mit den entsprechenden Konfigurationen geladen werden, um eine präzise und effiziente Verarbeitung zu gewährleisten.
Schließlich erfolgt die Weitergabe der vorverarbeiteten Daten an den K-Sampler. Der K-Sampler ist ein entscheidendes Element des Workflows, das für die Generierung des finalen Bildes verantwortlich ist. Basierend auf den vorherigen Schritten und den vorliegenden Daten nutzt der K-Sampler fortschrittliche Techniken, um ein hochwertiges und realistisches Bild zu erstellen, das die Pose der Person und die räumliche Tiefe der Szene genau widerspiegelt.
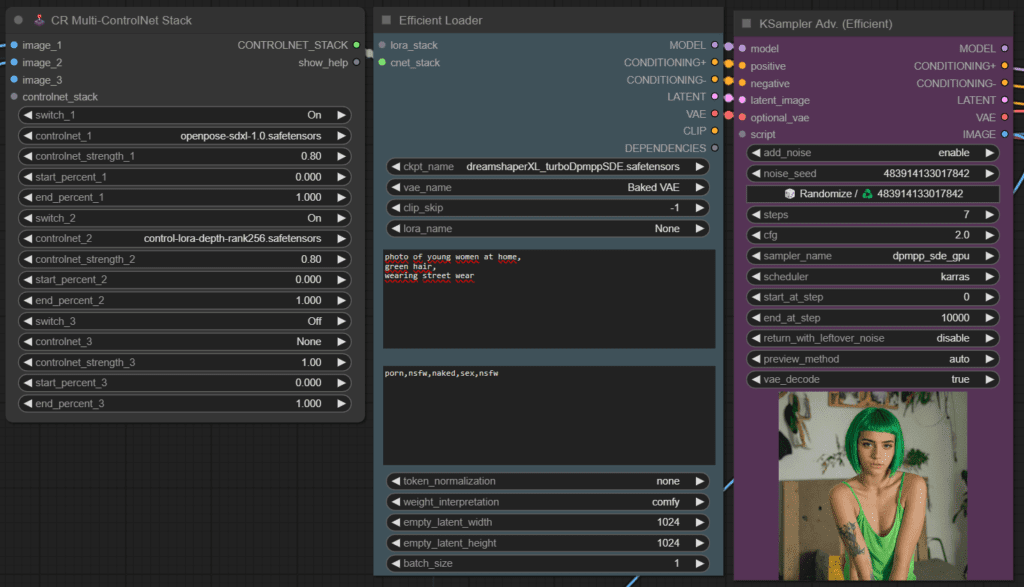
Das Ausgabebild, das wir generiert haben, spiegelt nicht nur die Gesichtszüge der Person, sondern auch die Tiefe der Szene äußerst zufriedenstellend wider.
